И от LLM будет польза
В прошлой статье было описано как поднять свой собственный сервис с LLM на базе ollama и моделью DeepSeek. Но в таком случае это получался банальный чатбот, которых в сети полным полно, этот разве что полностью под собственным контролем. Попробуем сделать из этого болтливого бота полезный инструмент.
А поможет нам в это проект ShellOracle. К СУБД Oracle не имеет ни малейшего отношения, а Oracle — это оракул, то есть предсказатель.
На сайте проекта https://github.com/djcopley/ShellOracle указана поддержка множества различных моделей и API, в том числе и ollama, на нем и остановимся, благо инстанс у нас уже есть.
Установка ShellOracle
Для установки будем использовать ВМ с развёрнутым openScaler 24.03 SP1, сама конфигурация ВМ довольно стандартна: 4 ядра и 4 Gb RAM, диск на 20 Gb.
Для установки будет использован инструмент pipx, который будет установлен через pip.
pip install pipx
Теперь можно установить и сам ShellOracle
pipx install shellorcale

Установка успешно завершена, но нам советуют поставить выполнить команду pipx ensurepath, которая автоматически дополнит переменную PATH, и нет нужды править это вручную.
pipx ensurepath

Чтобы изменения произошли необходимо перезайти в систему или перечитать файл .bashrc, пойдет по первому пути, перезайдем в систему.
После входа необходимо настроить shelloracle на работу с нашим сервисом ollama, для этого запустим конфигуратор shor:
shor configure

Необходимо указать адрес сервера, а так же наверно порт, если с адресом проблем нет, то вот с портом — надо узнать, на каком порту нас ждут. Для этого подключаемся к серверу с ollama:
lsof -i -n -P | grep ollama
![]()
Как видно выше порт для доступа по API — 11434, но проблема в том, что сервис слушает только loopback интерфейс, необходимо это исправить.
Узнав номер порта сразу настроим фаервол, что бы сетевой доступ сразу появился:
firewall-cmd —permanent —add-port=11434/tcp
firewall-cmd —reload

Фаервол настроен и теперь можно заняться настройкой ollama. Из документации к ollama следует, что адрес, на котором необходимо принимать запросы по API можно указать через переменную окружения OLLAMA_HOST. Останавливаем системную службу и пробуем запустить в консоли:
systemctl stop ollama
OLLAMA_HOST=183.16.4.148 ollama serve
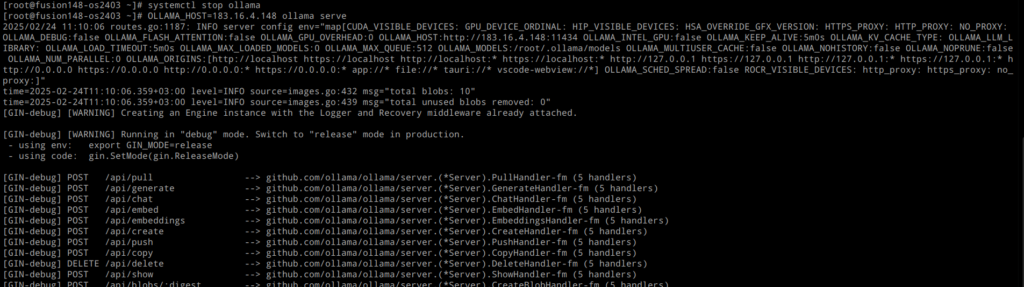
Ждём несколько секунд пока сервис запустится:
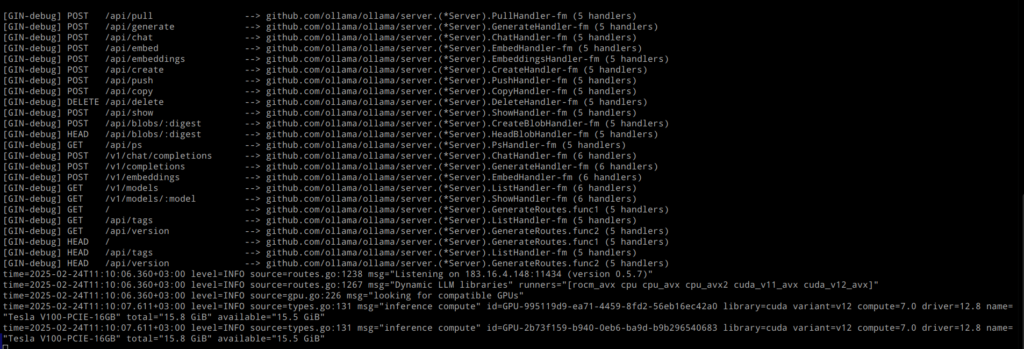
Сервис запущен и рапортует о наличии двух GPU с 16 Gb VRAM каждый. Теперь загрузим модель deepseek-r1:32b, для этого в соседней консоли запустим команду:
OLLAMA_HOST=183.16.4.148 ollama run deepseek-r1:32b

Модель успешно запустилась и даже ответила на тестовый запрос.
Проверим ещё раз, что именно порт 11434 готов принимать запросы:
lsof -i -n -P | grep ollama

Теперь можно вернутся к настройке oracleshell:
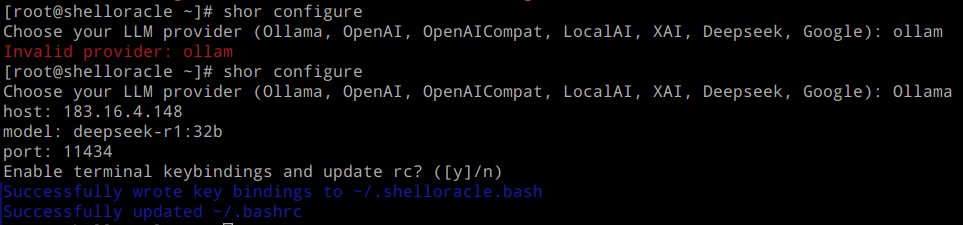
Указываем сервер, где работает ollama и имя запущенной модели deepseek-r1:32b, порт по умолчанию 11434, на этом настройка завершена. Необходимо перезайти в систему для перечитывания файла .bashrc.
Для выполнения запросов к модели необходимо нажать комбинацию клавиш CTRL+F, появится приглашение > для ввода запроса, что ж попробуем:

Как видно запрос вполне успешно выполнился и в конце, после размышлений, указана верная команда who.
Попробуем попросить не выводить своим размышления, а сразу давать команду:

Машина упорно сопротивляется, думаю тут проблема в самой модели deepseek, которая в первую очередь заточена на такой формат общения. Попробуем сменить модель на что-то попроще, например на qwen.
Для этого возвращаемся в консоль с запущенной deepseek и выходим командой /bye и запустим qwen:
OLLAMA_HOST=183.16.4.148 ollama run qwen:14b

Теперь необходимо указать новую модель в shellorcale, для этого опять запустим конфигуратор:
shor configure

Указываем новые вводные и выполняем перезаход в систему. Так же жмем CTRL+F и делаем запрос:

Получилось не сильно лучше, но попробуем попросить не делать размышления.

Уже лучше, но сама команда так себе. Попробуем что-то другое:

А этот запрос отработан на ура.
Таким образом уже можно попробовать использовать LLM для чего-то более осмысленного. Но и качество ответа так же напрямую зависит от используемой модели, чем больше модель тем лучше ответ.
В дополнение можно сказать, так как сервер теперь принимает запросы по сети, то можно к нему подключить несколько таких консолей и работать параллельно, а при наличии доступа к коммерческим моделями сразу настроить shelloracle на работу с ними.
