DevStore + AnythingLLM: разворачиваем локальный AI-ассистент за 15 минут
В статье расскажем о простом и быстром запуске варианта чат-бота c применением инструментов доступных в openEuler DevStation, работающего в нашем примере с документацией и при этом чат-бот не отправляет данные куда-то во внешнее облако. AnythingLLM — популярный open-source инструмент для создания локальных AI-ассистентов с RAG (Retrieval-Augmented Generation). Благодаря магазину приложений DevStore из состава openEuler его можно развернуть и сразу же использовать для проверки работы, что может стать полезным для дальнейшего изучения и систематизации информации из документов.
Что получим?
- Полностью локальный AI-ассистент для работы с документами;
- Поддержку работы с документами в форматах PDF, DOCX, Markdown, CSV и даже кода;
- Интеграцию с локальными моделями через Ollama;
- Веб-интерфейс для совместной работы.
Установка DevStore
Если DevStore ещё не установлен (поддерживается сразу из коробки в openEuler 25.09 DevStation или 24.03 LTS SP3 DevStation), то это можно сделать так:
sudo yum install -y dev-store
sudo systemctl restart dev-store
Проверяем порты (при необходимости открываем 3306 и 28080):
firewall-cmd —add-port=3306/tcp —permanent
firewall-cmd —add-port=28080/tcp —permanent
firewall-cmd —reload
Установка AnythingLLM из DevStore
- Открываем DevStore в браузере (http://localhost:28080 или адрес вашего сервера).
- Переключаемся на вкладку oeDeploy Plugin (плагины развёртывания).
- Нажимаем Синхронизировать в правом верхнем углу — получаем актуальный каталог.
- В поиске вводим AnythingLLM и нажимаем Download. Дожидаемся окончания загрузки.
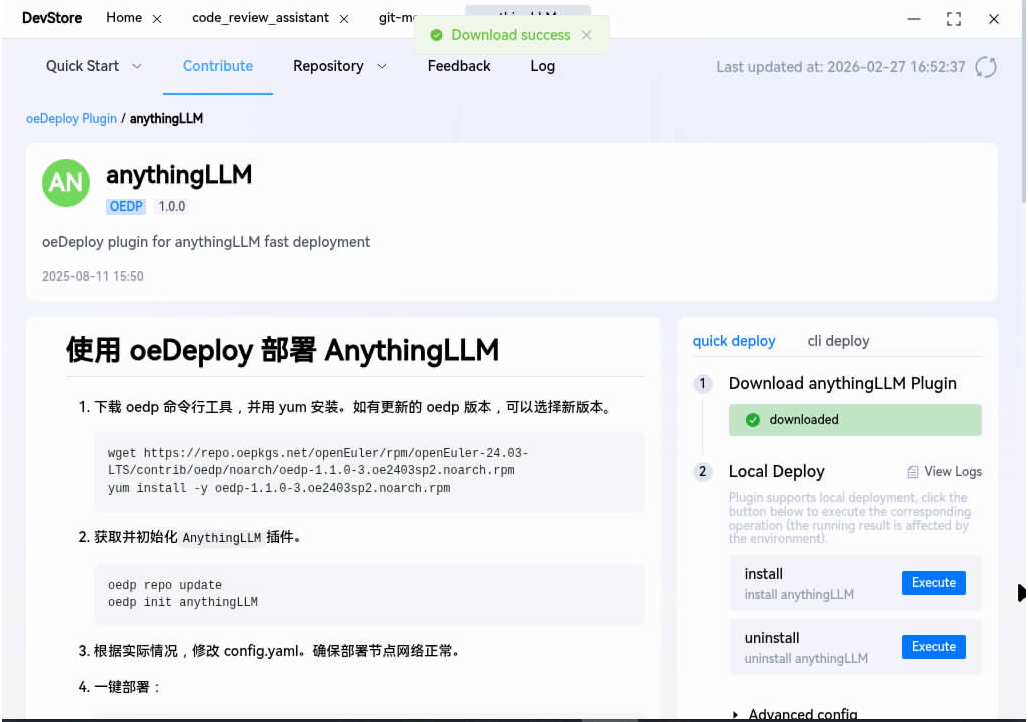
Развёртывание через oeDeploy
DevStore самостоятельно загрузит все необходимые файлы и Docker-образы. Затем выбираем операцию Install и нажимаем кнопку установки напротив Execute. Затем следим за логами в реальном времени через кнопку View Logs.
# DevStore автоматически выполняет примерно такие команды:
docker pull mintplexlabs/anythingllm:master
mkdir -p /opt/anythingllm/storage
docker run -d -p 3001:3001 \
—cap-add SYS_ADMIN \
-v /opt/anythingllm/storage:/app/server/storage \
-e STORAGE_DIR=»/app/server/storage» \
mintplexlabs/anythingllm:master
Развёртывание Ollama
Для работы чат-бота потребуется запустить локально ИИ модель (в нашем примере это будет сравнительно небольшая модель Llama 3.1 8B) и для этого нужна установка Ollama в Docker контейнере. Для этого выполним следующие команды в консоли:
sudo docker run -d -v ollama:/root/.ollama -p 11434:11434 ollama/ollama
sudo docker exec -itd ollama ollama run llama3.1:8b
Через 2-3 минуты всё готово. Модель запущена и готова к дальнейшему использованию.
Первая настройка
Открываем http://your-server-IP:3001 и проходим мастер настройки.
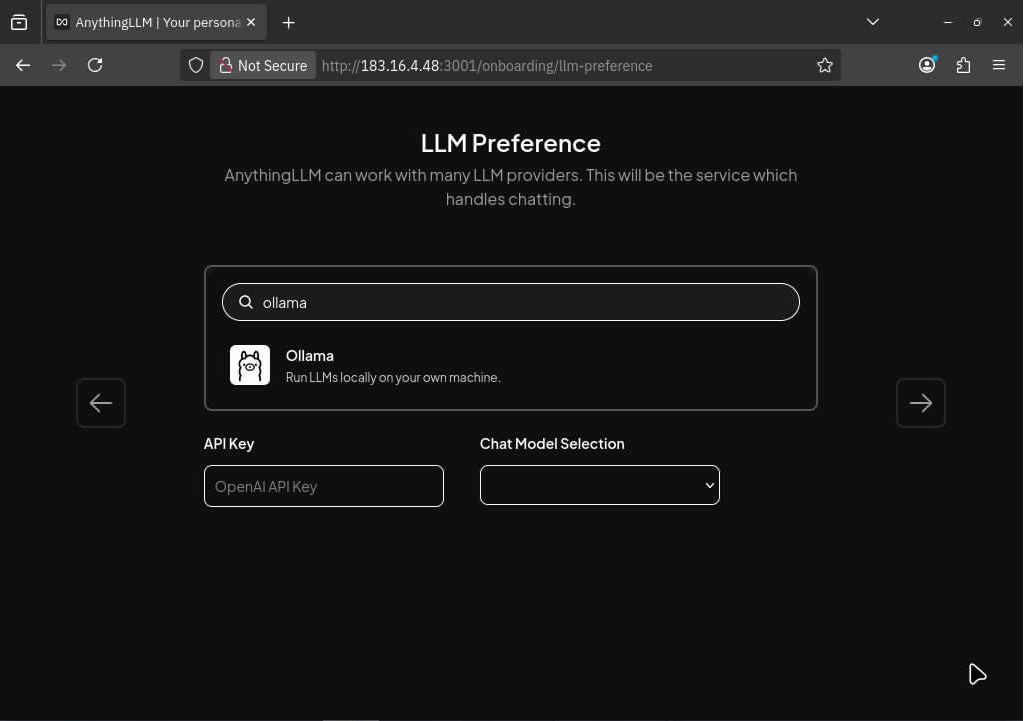
- Выбираем LLM-провайдер — для локальной работы указываем Ollama.
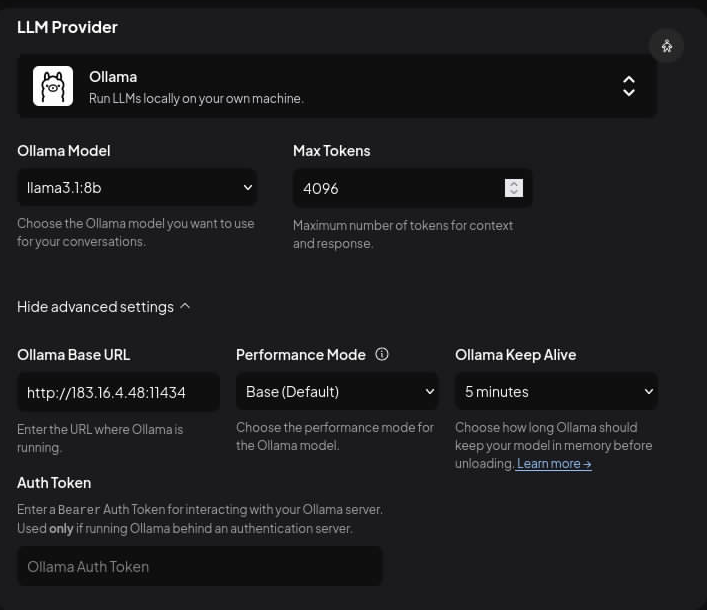
- Настраиваем Ollama — указываем URL http://your-server-IP:11434 (если Ollama запущена на том же сервере).
- Выбираем модель — рекомендуем Llama3.1:8b для начала.
- Embedding-модель — выбираем nomic-embed-text для векторного поиска
Загружаем документы и тестируем
Создаём рабочее пространство (Workspace) — например, как у нас vspace или любое другое имя:
- Нажимаем кнопку Attach a file to this chat.
- Перетаскиваем, например, PDF с инструкциями, Markdown-файлы с API-документацией или CSV с данными.
- AnythingLLM автоматически разбивает документы на фрагменты (chunking) и создаёт на её основе векторную базу LanceDB.
Мы для примера взяли Technical White Paper для openEuler 24.03 LTS SP3.
После анализа документа делаем такой prompt: «What you know about GMEM technology?» — и получаем ответ на основе загруженных документов.
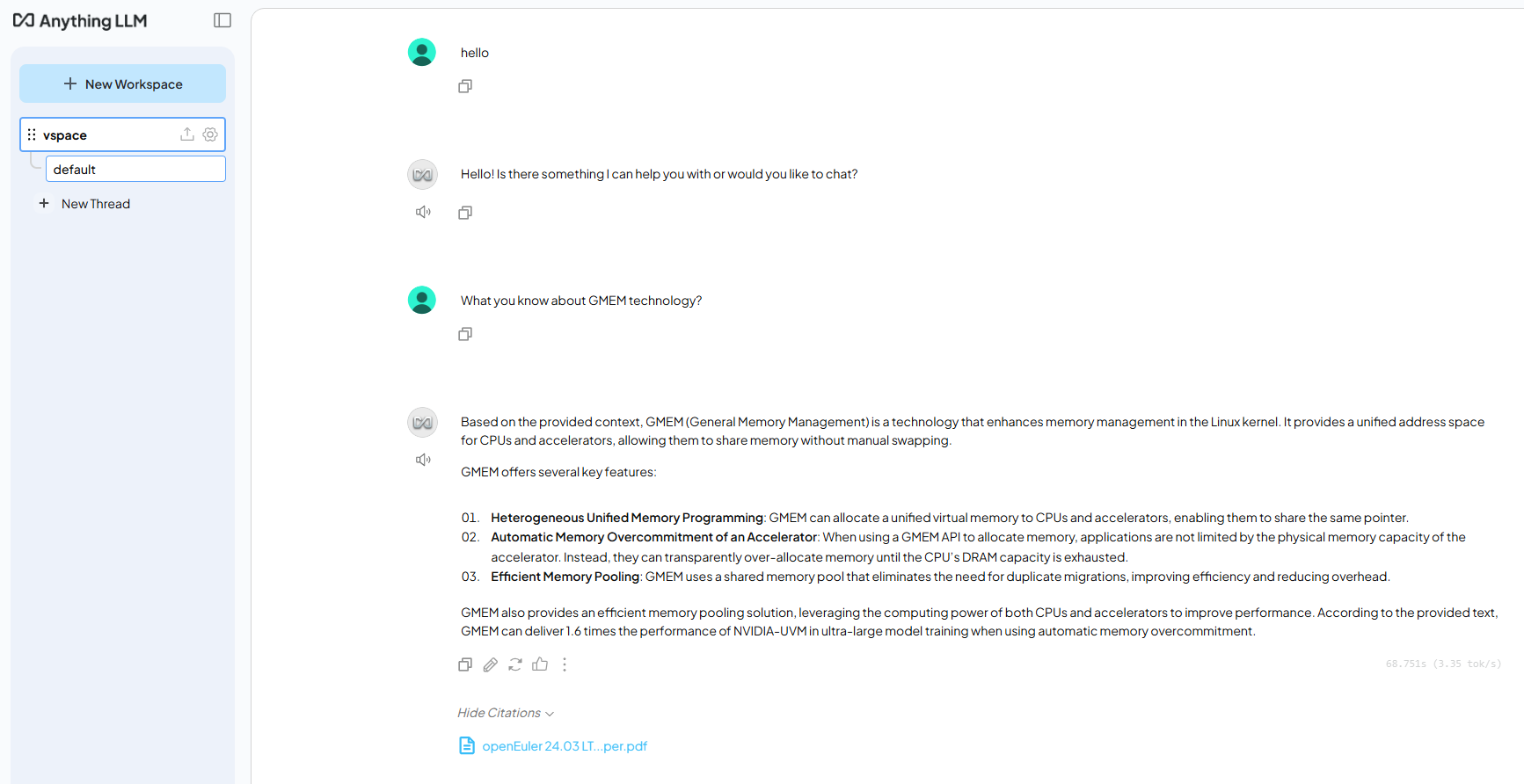
Видно, что модель создала ответ на наш запрос, взяв информацию из загруженного ранее нами pdf-файла.
Заключение
DevStore превращает развёртывание сложного AI-стека из задачи на полдня в 15-минутную процедуру. Всё, что требуется от администратора — выбрать нужный плагин и выполнить небольшое количество действий для запуска ИИ модели. Остальное openEuler делает сама: от загрузки образов до настройки сетевого доступа.
Попробуйте развернуть AnythingLLM через DevStore уже сегодня — и получите локального AI-ассистента, который знает вашу документацию лучше, чем любой сотрудник.