Тестирование запуска контейнеров внутри виртуальных машин в кластере kubernetes
Вводная часть
Все, кто знаком с запуском приложений внутри контейнера на операционной системе Linux знает, что в основе технологии контейнеризации лежат два механизма ядра Linux — пространства имён (namespaces) и контрольные группы (cgroup). Оба эти механизма предназначены для создания ограничений со стороны операционной системы для процесса, который запущен внутри контейнера. Так, механизм пространства имён наделяет контейнер собственным набором идентификаторов процессов, собственным набором сетевых интерфейсов, пользовательскими идентификаторами, файловой системой и собственным именем хоста внутри контейнера. Механизм контрольных групп следит за количеством ресурсов (времени работы CPU, количество потреблённой памяти и т.д.) которые потребляет процесс запущенный внутри контейнера. Казалось бы, что существующих механизмов ограничений вполне достаточно, чтобы с уверенностью можно было сказать, что процесс запущенный внутри контейнера надёжно отгорожен от основной системы и не сможет нанести ей вред в случае какой-либо своей компрометации. Но, увы, так было бы только в идеальном мире, где программисты пишут свой код без единой ошибки. А в нашем мире мы регулярно читаем про найденные уязвимости в реализации различных инструментов для запуска контейнеров, которые позволяют обойти наложенные на контейнеры ограничения.
Все выявленные подобные уязвимости приводить здесь в качестве иллюстрации смысла нет, но привести ссылки на некоторые можно. Так, в 2019 в runc была выявлена уязвимость CVE-2019-5736 (подробнее почитать про неё можно здесь: https://security-tracker.debian.org/tracker/CVE-2019-5736), которая позволяла злоумышленнику изменить исполняемый файл runc и получить привилегии пользователя root на стороне хост-системы. Так как runc используют многие системы контейнеризации, то эта уязвимость затронула docker, podman, flatpak, cri-o, containerd. В 2021 году, опять-таки в runc, выявлена уязвимость CVE-2021-30465 (ознакомится с подробностями можно по ссылке: https://security-tracker.debian.org/tracker/CVE-2021-30465). В 2022 отличилась уже CRI-O уязвимостью CVE-2022-0811 (подробности тут: https://security-tracker.debian.org/tracker/CVE-2022-0811). И буквально недавно нас снова настигла новость о очередной уязвимости в runc CVE-2024-21626 (читаем по ссылке: https://security-tracker.debian.org/tracker/CVE-2024-21626), которая в очередной раз продемонстрировала возможность получить доступ к файловой системе хост-системы из запущенного на ней контейнера.
Поэтому совершенно не удивительно, что для улучшения защиты от потенциальных уязвимостей в программном обеспечении запуска контейнеров начали применять дополнительные меры по добавлению уровней изоляции запущенного в контейнере приложения от хост-системы. Одним из таких механизмов является kata containers (сайт проекта https://katacontainers.io/, сайт с исходным открытым кодом https://github.com/kata-containers/kata-containers) — проект по созданию легковесных виртуальных машин, предназначенных для запуска внутри них процессов на базе образов контейнеров.
Наглядно ознакомится с архитектурой данного подхода можно на иллюстрации взятой с сайта https://docs.openeuler.org:
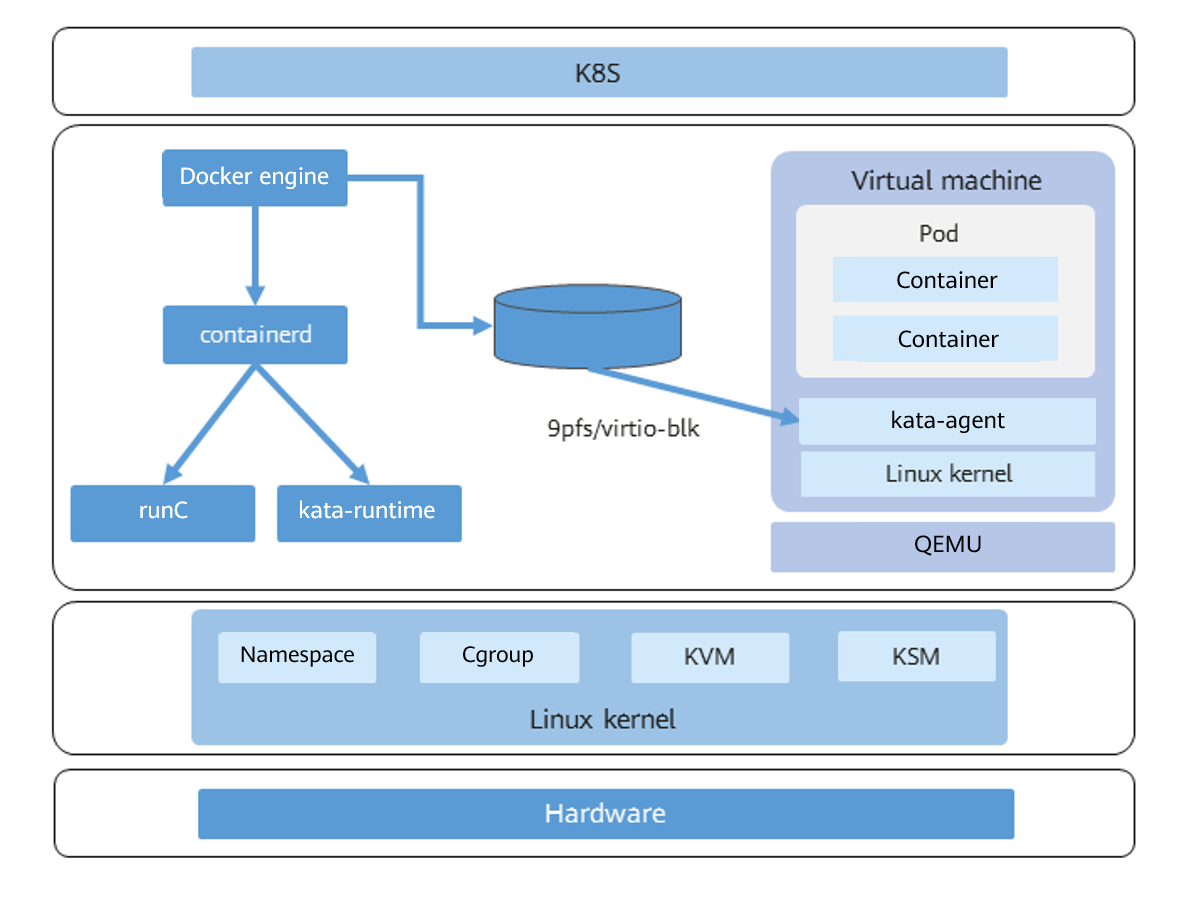
Итак, вводных слов сказано достаточно, предлагается перейти уже к практике!
Установка и настройка связки kata containers, iSulad, k8s
Цель
Итак, давайте для начала определимся с целью нашей сегодняшней практики. В интернете есть много статей про установку kata и её интеграцию с docker, а также запуск с её помощью одиночных контейнеров. Дескать, «вот контейнер запустился, отлично, всем спасибо, доклад окончен». Мы пойдём немного дальше. Во-первых, так как в нашем дистрибутиве есть своя система контейнеризации iSulad — мы будем опираться на неё. Во-вторых, мне не интересно запустить одинокий контейнер, гораздо интереснее запустить сразу группу, да не просто группу, чтобы это ещё и работало в под управлением модного kubernetes. Итак, мы будем рассматривать в статье связку kata-containers + iSulad + kubernetes.
Для тех же, кому всё-таки интересно ознакомится с базовыми понятиями и пока достаточно запустить один контейнер — можно порекомендовать документацию https://docs.openeuler.org/en/docs/22.03_LTS_SP3/docs/Container/secure-container.html
А также, сразу хочется оговориться, что в данной статье мы не будем рассматривать установку и развёртывание самого кластера k8s, а ограничимся установкой, настройкой и добавлением в кластер нового рабочего узла, который будет работать на указанной выше связке.
Итак, приступим!
Подготовка к установке
Для начала, давайте посмотрим лист описания узлов нашего кластера k8s:
$ kubectl get no -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-2309-m1 Ready control-plane,master 95d v1.22.17 172.17.3.61 <none> openScaler 23.09 6.4.0-10.1.0.20.os2309.x86_64 iSulad://2.1.3
k8s-2309-m2 Ready control-plane,master 94d v1.22.17 172.17.3.62 <none> openScaler 23.09 6.4.0-10.1.0.20.os2309.x86_64 iSulad://2.1.3
k8s-2309-m3 Ready control-plane,master 94d v1.22.17 172.17.3.63 <none> openScaler 23.09 6.4.0-10.1.0.20.os2309.x86_64 iSulad://2.1.3
k8s-2309-w1 Ready <none> 94d v1.22.17 172.17.3.64 <none> openScaler 23.09 6.4.0-10.1.0.20.os2309.x86_64 iSulad://2.1.3
Из этого описания мы видим, что он развёрнут на базе ОС OpenScaler 23.09, при этом в качестве runtime у него используется iSulad 2.1.3, версия k8s 1.22.17 (используемая у нас версия iSulad 2.1.3 максимально поддерживает версию k8s 1.22). Узлы управления имеют адреса 172.17.3.61, 172.17.3.62, 172.17.3.63. Единственный рабочий узел в этом кластере имеет ip адрес 172.17.3.64.
Для проведения нашего тестирования мы будем использовать новый узел с ip 172.17.3.53. Давайте приступим к его установке и настройке.
Здесь стоит сделать ещё одно небольшое отступление, чтобы пояснить, что данная статья не претендует на охват всех аспектов производимых манипуляций и концентрируется только на важных аспектах непосредственно затрагиваемой в заголовке статьи темы. Именно по этой причине такие действия как установка ОС и некоторые производимые настройки не описываются столь подробно, подразумевая, что у читателя уже имеется опыт по выполнению данных манипуляций и приведённых в статье кратких описаний должно хватить для понимания.
Установка ОС
В качестве ОС мы выбираем стабильную версию openScaler 22.03 SP2 LTS.
При её установке выберем тип установки «Минимальный», настроим ip адрес (172.17.3.53), шлюз, DNS сервер, зададим имя хоста (давайте назовём этот узел «k8s-kata»).
Дожидаемся установки пакетов, нажимаем кнопку завершения установки, наблюдаем за успешной перезагрузкой сервера и заходим в приветливую консоль свежеустановленного openScaler.
Настройка узла под k8s
Так как мы добавляем новый узел в наш кластер, то необходимо, чтобы все узлы могли обращаться к нему по имени и он сам знал соответствия имён узлов их ip адресам. Поэтому, добавляем в файл /etc/hosts на всех узлах информацию про наш новый узел и актуализируем файл /etc/hosts на нашем новом узле k8s-kata, приведя его к виду:
172.17.3.61 k8s-2309-m1
172.17.3.62 k8s-2309-m2
172.17.3.63 k8s-2309-m3
172.17.3.64 k8s-2309-w1
172.17.3.53 k8s-kataДалее, мы выполняем ряд действий, которые так или иначе требует программное обеспечение kubernetes при своей установке.
Отключаем swap на k8s-kata:
# swapoff -a
Не забываем закоментировать в /etc/fstab:
#/dev/mapper/openscaler-swap none swap defaults 0 0Отключаем SELinux.
Далее нам предстоит настроить сетевой фильтр. Если делать всё по правильному — то нам придётся прописать в правила доступ на все порты, которые будут использовать вспомогательные службы kubernetes, а также разрешить доступы на публикуемые сервисы. Так как мы разворачиваем узел исключительно в демонстрационных целях, то мы просто отключим сервис firewalld, чтобы облегчить труд тех читателей, которые попробуют повторить данный эксперимент:
# systemctl disable firewalld# systemctl stop firewalldДалее, нам надо обеспечить автозагрузку модуля ядра br_netfilter, для этого мы подготавливаем файл /etc/modules-load.d/br_netfilter.conf с содержимым:
br_netfilterЗатем, нам предстоит включить в настройках sysctl переменную:
net.ipv4.ip_forward = 1Установка kata-containers и iSulad
Ну что же, узел почти настроен, начинаем ставить на него необходимые пакеты.
Для начала мы поставим пакеты с kata-containers и пакеты виртуализации qemu:
# dnf install kata-containers qemu qemu-system-x86_64 Далее, подготовим конфигурационный файл для kata-containers: /usr/share/defaults/kata-containers/configuration.toml
[hypervisor.qemu] path = "/usr/bin/qemu-kvm" kernel = "/var/lib/kata/kernel" initrd = "/var/lib/kata/kata-containers-initrd.img" machine_type = "pc" kernel_params = "agent.log=debug" hypervisor_params = "" firmware = "" machine_accelerators="" default_vcpus = 1 default_maxvcpus = 0 default_bridges = 1 default_memory = 2048 disable_block_device_use = false shared_fs = "virtio-9p" virtio_fs_daemon = "/usr/bin/virtiofsd" virtio_fs_cache_size = 1024 virtio_fs_extra_args = [] virtio_fs_cache = "always" block_device_driver = "virtio-blk" block_device_cache_set = true block_device_cache_direct = true enable_iothreads = false enable_vhost_user_store = false vhost_user_store_path = "/var/run/kata-containers/vhost-user" enable_debug = true hotplug_vfio_on_root_bus = true disable_vhost_net = true [factory] [proxy.kata] path = "/usr/bin/kata-proxy" enable_debug = true [shim.kata] path = "/usr/bin/kata-shim" enable_debug = true [agent.kata] enable_debug = true kernel_modules=[] enable_blk_mount = true [netmon] path = "/usr/bin/kata-netmon" enable_debug = true [runtime] enable_debug = true internetworking_model = "tcfilter" disable_guest_seccomp=true enable_compat_old_cni = true sandbox_cgroup_only=false sandbox_cgroup_with_emulator = true experimental=[]
Теперь можно перейти к установке системы контейнеризации iSulad:
# dnf install iSuladДожидаемся конца установки пакетов и сделаем ещё одно отступление. А именно, перед настройкой iSulad давайте подготовим на сервере k8s-kata на диске /dev/sdb тонкий пул LVM, который (согласно рекомендациям с https://gitee.com/openeuler/iSulad/blob/master/docs/manual/k8s_integration.md) мы будем использовать для хранения данных системы контейнеризации. В качестве storage driver в конфигурационном файле iSulad мы укажем «devicemapper».
Для этого мы выполним ряд команд:
# pvcreate /dev/sdb
# vgcreate isula /dev/sdb
# lvcreate --wipesignatures y -n thinpool isula -l 95%VG
# lvcreate --wipesignatures y -n thinpoolmeta isula -l 1%VG
# lvconvert -y --zero n -c 64K --thinpool isula/thinpool --poolmetadata isula/thinpoolmeta
# touch /etc/lvm/profile/isula-thinpool.profile
# cat << EOF > /etc/lvm/profile/isula-thinpool.profile
activation {
thin_pool_autoextend_threshold=80
thin_pool_autoextend_percent=20
}
EOF
# lvchange --metadataprofile isula-thinpool isula/thinpoolОтлично, теперь подготовим конфигурационный файл /etc/isulad/daemon.json:
{
«group»: «isula»,
«default-runtime»: «lcr»,
«graph»: «/var/lib/isulad»,
«state»: «/var/run/isulad»,
«log-level»: «ERROR»,
«pidfile»: «/var/run/isulad.pid»,
«log-opts»: {
«log-file-mode»: «0600»,
«log-path»: «/var/lib/isulad»,
«max-file»: «1»,
«max-size»: «30KB»
},
«log-driver»: «stdout»,
«container-log»: {
«driver»: «json-file»
},
«hook-spec»: «/etc/default/isulad/hooks/default.json»,
«start-timeout»: «2m»,
«storage-driver»: «devicemapper»,
«storage-opts»: [
«dm.thinpooldev=/dev/mapper/isula-thinpool»,
«dm.fs=ext4»,
«dm.min_free_space=10%»
],
«registry-mirrors»: [
«docker.io»
],
«insecure-registries»: [
],
«pod-sandbox-image»: «registry.aliyuncs.com/google_containers/pause:3.5»,
«native.umask»: «normal»,
«network-plugin»: «cni»,
«cni-bin-dir»: «/opt/cni/bin»,
«cni-conf-dir»: «/etc/cni/net.d»,
«image-layer-check»: false,
«use-decrypted-key»: true,
«insecure-skip-verify-enforce»: false,
«cri-runtimes»: {
«kata»: «io.containerd.kata.v2»
},
«enable-cri-v1»: true,
«runtimes»: {
«kata-runtime»: {
«path»: «/usr/bin/kata-runtime»,
«runtime-args»: [
«—kata-config»,
«/usr/share/defaults/kata-containers/configuration.toml»
]
}
}
}
Создаём каталоги:
# mkdir /var/lib/isulad/engines /var/lib/isulad/sandboxИ запускаем iSulad:
# systemctl enable --now isuladОтлично. Половина дела сделана, теперь приступаем к проверке работы связки iSulad и kata-containers.
Проверка работы связки iSulad и kata-containers
Запуск простого контейнера с использованием виртуальной машины
Как вы уже, наверное, заметили из конфигурационного файла iSulad у нас указано несколько runtime для запуска контейнеров. То есть, у нас сохраняется возможность запускать классические контейнеры без использования механизмом виртуализации, а так же появляется возможность путём явного указания нужного runtime (в конфигурационном файле он обозначен как kata-runtime) запускать защищённые контейнеры с применением технологии виртуализации. Давай протестируем это.
Выполним следующую команду:
# isula run -tid —runtime «kata-runtime» —net=none —name test busybox:latest sh
9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce
Здесь мы запустили оболочку sh в контейнере, имя которому мы дали test, с использованием образа busybox, без использования сети (kata поддерживают только CNI сети, а их мы будем использовать в k8s) и явным указанием использовать kata-runtime.
Если в соседнем терминале дать команду:
# isula ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9164a168539e busybox:latest «sh» 15 seconds ago Up 13 seconds test
То мы увидим наш запущенный контейнер.
Если мы посмотрим на описание характеристик контейнера, то увидим, что запущен он с указанным runtime:
# isula inspect 9164a168539e | grep Runtime
«Runtime»: «kata-runtime»,
Давайте теперь посмотрим как это выглядит со стороны kata.
В терминале на сервере k8s-kata дадим команду:
# kata-runtime list
ID PID STATUS BUNDLE CREATED OWNER
9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce 5109 running /var/lib/isulad/engines/kata-runtime/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce 2024-02-14T10:35:01.385989478Z #0
Да, вы видим, что с этим ID есть запущенная виртуальная машина kata.
Теперь, давайте посмотрим, что у нас происходит со стороны использования системы хранения. Выполним команду и рассмотрим её вывод:
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 600M 0 part /boot/efi
├─sda2 8:2 0 1G 0 part /boot
└─sda3 8:3 0 48,4G 0 part
├─openscaler-root 253:0 0 43,4G 0 lvm /var/lib/isulad/mnt
│ /
└─openscaler-swap 253:1 0 5G 0 lvm
sdb 8:16 0 100G 0 disk
├─isula-thinpool_tmeta 253:2 0 1020M 0 lvm
│ └─isula-thinpool 253:4 0 95G 0 lvm
│ └─container-253:0-1964275-9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce 253:5 0 10G 0 dm /var/lib/isulad/storage/devicemapper/mnt/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce
└─isula-thinpool_tdata 253:3 0 95G 0 lvm
└─isula-thinpool 253:4 0 95G 0 lvm
└─container-253:0-1964275-9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce 253:5 0 10G 0 dm /var/lib/isulad/storage/devicemapper/mnt/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce
sr0 11:0 1 1024M 0 rom
Как мы видим у нас появились логические тома, которые были подключены к запущенной виртуальной машине kata.
Мы всё время говорим про виртуальную машину. А где она?
Да вот же:
# ps -ef | grep qemu-kvm
root 5089 5071 0 13:34 ? 00:00:02 /usr/bin/qemu-kvm -name sandbox-9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce -uuid ce502dda-518d-4aa1-afe1-8312c2d67680 -machine pc,accel=kvm -cpu host,pmu=off -qmp unix:/run/vc/vm/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/qmp.sock,server,nowait -m 2048M,slots=10,maxmem=15712M -device pci-bridge,bus=pci.0,id=pci-bridge-0,chassis_nr=1,shpc=on,addr=2,romfile= -device virtio-serial-pci,disable-modern=true,id=serial0,romfile= -device virtconsole,chardev=charconsole0,id=console0 -chardev socket,id=charconsole0,path=/run/vc/vm/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/console.sock,server,nowait -object rng-random,id=rng0,filename=/dev/urandom -device virtio-rng-pci,rng=rng0,romfile= -device virtserialport,chardev=charch0,id=channel0,name=agent.channel.0 -chardev socket,id=charch0,path=/run/vc/vm/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/kata.sock,server,nowait -device virtio-9p-pci,disable-modern=true,fsdev=extra-9p-kataShared,mount_tag=kataShared,romfile= -fsdev local,id=extra-9p-kataShared,path=/run/kata-containers/shared/sandboxes/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/shared,security_model=none -global kvm-pit.lost_tick_policy=discard -vga none -no-user-config -nodefaults -nographic -daemonize -object memory-backend-ram,id=dimm1,size=2048M -numa node,memdev=dimm1 -kernel /var/lib/kata/kernel -initrd /var/lib/kata/kata-containers-initrd.img -append tsc=reliable no_timer_check rcupdate.rcu_expedited=1 i8042.direct=1 i8042.dumbkbd=1 i8042.nopnp=1 i8042.noaux=1 noreplace-smp reboot=k console=hvc0 console=hvc1 iommu=off cryptomgr.notests net.ifnames=0 pci=lastbus=0 debug panic=1 nr_cpus=8 agent.use_vsock=false agent.log=debug agent.log=debug -pidfile /run/vc/vm/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/pid -D /run/vc/vm/9164a168539e3ee97ea1a9c7ac5d6d73368a3456558bbde1fd6f7c73b7caf4ce/qemu.log -smp 1,cores=1,threads=1,sockets=8,maxcpus=8
Давайте теперь удалим контейнер командой:
# isula rm -f test
Заметим, что при этом удалится и виртуальная машина, и выделенные блочные тома LVM.
Подводя маленький итог, заметим, что мы только что продемонстрировали самый базовый пример использования виртуальной машины в качестве runtime для контейнеризации.
Отлично, но хотелось бы понять работу kata несколько глубже, поэтому давайте теперь попробуем попасть внутрь виртуальной машины, в которой запускается контейнер.
Заглядывание внутрь виртуальной машины
Сказано — сделано!
Правим конфигурационный файл /usr/share/defaults/kata-containers/configuration.toml и добавляем параметр ядра «agent.debug_console»:
kernel_params = «agent.log=debug agent.debug_console»
и запускаем контейнер заново, но в этот раз запустим nginx:
# isula run -d —runtime «kata-runtime» —net=none —name web nginx:latest
6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509
Так же, проверям, что контейнер запустился:
# isula ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6a7385149aa0 nginx:latest «/docker-entrypoin…» 8 seconds ago Up 7 seconds web
Мы так же видим его в списке виртуальных машин:
# kata-runtime list
ID PID STATUS BUNDLE CREATED OWNER
6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509 20437 running /var/lib/isulad/engines/kata-runtime/6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509 2024-02-14T14:26:32.79795615Z #0
По хорошему можно попасть в контейнер используя метод exec команды kata-runtime. Вот так:
# kata-runtime exec 6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509
Но у нас эта команда падает с ошибкой
rpc error: code = Internal desc = Could not run process: container_linux.go:349: starting container process caused «panic from initialization: runtime error: index out of range…
Эта ошибка будет поводом нашей темы с разработчиками, но не останавливаться же нам на полпути только из-за какой-то ошибки? Не будем расстраиваться, внутрь мы всё равно попадём, но несколько более сложным путём.
Мы знаем id контейнера: 6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509
Путь к сокету консоли виртуальной машины расположен по пути:
/var/run/vc/vm/6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509/console.sock
Используем команду socat, чтобы открыть консоль виртуальной машины:
# socat «stdin,raw,echo=0,escape=0x11» «unix-connect:/var/run/vc/vm/6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509/console.sock»
нажимаем Enter и мы оказались внутри виртуальной машины (напоминаю, что запущена она на основе ядра /var/lib/kata/kernel и initrd образа /var/lib/kata/kata-containers-initrd.img)
Находясь внутри этой виртуальной машины, мы можем посмотреть запущенные внутри неё процессы:
# ps
PID USER TIME COMMAND
1 0 0:00 /init
2 0 0:00 [kthreadd]
3 0 0:00 [rcu_gp]
4 0 0:00 [rcu_par_gp]
5 0 0:00 [kworker/0:0-eve]
6 0 0:00 [kworker/0:0H-ev]
7 0 0:00 [kworker/u16:0-e]
8 0 0:00 [mm_percpu_wq]
9 0 0:00 [ksoftirqd/0]
10 0 0:00 [rcu_sched]
11 0 0:00 [migration/0]
12 0 0:00 [cpuhp/0]
13 0 0:00 [kdevtmpfs]
14 0 0:00 [netns]
15 0 0:00 [oom_reaper]
16 0 0:00 [writeback]
17 0 0:00 [kcompactd0]
18 0 0:00 [ksmd]
28 0 0:00 [cryptd]
29 0 0:00 [kworker/0:1-eve]
41 0 0:00 [kintegrityd]
42 0 0:00 [kblockd]
43 0 0:00 [blkcg_punt_bio]
44 0 0:00 [rpciod]
45 0 0:00 [kworker/0:1H-kb]
46 0 0:00 [kworker/u17:0]
47 0 0:00 [xprtiod]
49 0 0:00 [kswapd0]
50 0 0:00 [nfsiod]
51 0 0:00 [xfsalloc]
52 0 0:00 [xfs_mru_cache]
54 0 0:00 [khvcd]
55 0 0:00 [hwrng]
56 0 0:00 [ixgbe]
57 0 0:00 [ixgbevf]
58 0 0:00 [i40e]
59 0 0:00 [iavf]
60 0 0:00 [vfio-irqfd-clea]
61 0 0:00 [dm_bufio_cache]
62 0 0:00 [ipv6_addrconf]
67 0 0:00 /bin/sh
76 0 0:00 [kworker/u16:1]
78 0 0:00 [jbd2/vda-8]
79 0 0:00 [ext4-rsv-conver]
82 0 0:00 nginx: master process nginx -g daemon off;
109 101 0:00 nginx: worker process
124 0 0:00 ps
И среди процессов мы видим наш процесс nginx, которые запущен прямо внутри виртуалки.
Не выходя из виртуальной машины дадим команду mount и увидим, что образ nginx:latest смонтирован по пути:
/dev/vda on /run/kata-containers/shared/containers/6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509 type ext4 (rw,relatime,stripe=16)
перейдём по этому пути:
# cd /run/kata-containers/shared/containers/6a7385149aa0b12deab566b0fdca3d71fa47ce16c80e1161dca22ca48e876509/rootfs/
и увидим файлы из образа nginx:latest
Для выхода из виртуальной машины нажмём Control +q
Подключение сервера с iSulad и kata containers в кластер kubernetes
Ну что же, настала пора подключить наш сервер к существующему кластеру, для этого на этот сервер мы должны установить и запустить соответствующий софт. Приступим.
Добавляем репозиторий:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgУстанавливаем пакеты:
# dnf install -y kubeadm-1.22.17-0 kubectl-1.22.17-0 kubelet-1.22.17-0Активируем, но не запускаем сервис kubelet:
# systemctl enable kubeletДаём команду на присоединение к кластеру:
# kubeadm join 172.17.3.100:16443 \
--token zn7x2p.8x99o14i31wgxwvd \
--discovery-token-ca-cert-hash sha256:5b0cf34f81645f11c00174e63b1266050ce1527c3c5825069b06f422dbd00166 \
--cri-socket=unix:///var/run/isulad.sockЗаметьте, что kubeadm мы передаём в опции —cri-socket путь сокета нашего iSulad, чтобы kubelet знал, где он будет запускать контейнеры.
Давайте ещё раз посмотрим на перечень наших узлов кластера kubernetes:
$ kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-2309-m1 Ready control-plane,master 96d v1.22.17
k8s-2309-m2 Ready control-plane,master 96d v1.22.17
k8s-2309-m3 Ready control-plane,master 96d v1.22.17
k8s-2309-w1 Ready <none> 96d v1.22.17
k8s-kata Ready <none> 55s v1.22.17
И здесь мы уже видим, что в кластере появился ещё один узел k8s-kata, который в статусе Ready. Отлично, мы стали ещё ближе к заявленной в начале статьи цели.
Запуск приложения в кластере kubernetes с использованием kata
Теперь пришла пора собственно реализовать то, ради чего писалась вся статья.
Нам надо запустить какое-нибудь тестовое приложение в кластере.
Тут нам придётся сделать очередное маленькое отступление, чтобы пояснить, каким образом kubernetes должен будет понять, что данное приложение надо будет запустить не в классическом контейнере, а в выделенной виртуальной машине. Достигается это использованием механизма Runtime Class (подробнее о нём можно почитать тут: https://kubernetes.io/docs/concepts/containers/runtime-class/). Кратко можно сказать так, что в настройках нашего CRI-совместимого runtime (в нашем случае iSulad) мы должны описать runtime который будет запускать kata виртуальные машины. В нашем случае (смотри файл /etc/isulad/daemon.json) он описан и называется kata-runtime. Поэтому мы должны создать теперь объект типа RuntimeClass и указать в нём handler с таким же названием — «kata-runtime».
Переходим от слов к делу. Давайте подготовим файл test-kata-app.yaml со следующим содержимым:
kind: RuntimeClass
apiVersion: node.k8s.io/v1
metadata:
name: kata-runtime
handler: kata-runtime
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo2
namespace: test-kata
labels:
app: echo2
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: echo2
template:
metadata:
labels:
app: echo2
version: v1
spec:
runtimeClassName: kata-runtime
containers:
- name: echo2
image: mendhak/http-https-echo
ports:
- containerPort: 8080
name: http-echo2
---
apiVersion: v1
kind: Service
metadata:
name: echo2
namespace: test-kata
spec:
type: LoadBalancer
selector:
app: echo2
version: v1
ports:
- name: http-echo2
port: 8080
targetPort: http-echo2
protocol: TCP
Здесь, опытный глаз кубоведа (или кому как нравится — кубовода) сразу выделит, что помимо заявленного ранее RuntimeClass мы описываем запуск deployment приложения и службу (типа LoadBalancer) к нему в namespace test-kata, которое мы забыли создать заблаговременно. Обращаем внимание на следующую строчку в спецификации к контейнеру:
runtimeClassName: kata-runtime
Именно она указывает какой runtime должен быть выбран при запуске этого контейнера.
В качестве приложения мы берём докер образ проекта https://github.com/mendhak/docker-http-https-echo, представляющего собой лёгкий веб сервер, который просто в ответе отдаёт всю информацию по HTTP запросу. Очень удобно для проведения тестирований. А служба LoadBalancer позволяет получить ip адрес, по которому мы сможем обращаться к нашему приложению.
Давайте теперь применим этот файл командой
$ kubectl apply -f test-kata-app.yaml
И посмотрим на успешно запущенный контейнер:
$ kubectl -n test-kata get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
echo2-5575f6f55-mf9s4 1/1 Running 0 19s 10.122.170.83 k8s-kata <none> <none>
Отмечаем для себя, что благодаря магии k8s наш контейнер запустился сразу на нужном узле. На самом деле магии тут ноль, просто планировщик не нашёл в кластере k8s другого узла с нужным runtime 🙂
Давайте перейдём в консоль сервера k8s-kata и выполним уже привычную и знакомую нам команду:
# kata-runtime list
ID PID STATUS BUNDLE CREATED OWNER
360301fde1b12a641c52703f43583cdbb25f6c6b10f43e6a1cb0d09af56eb6fa 22433 running /var/lib/isulad/engines/kata-runtime/360301fde1b12a641c52703f43583cdbb25f6c6b10f43e6a1cb0d09af56eb6fa 2024-02-15T09:50:33.259219346Z #0
7b0e9819871e76ea2177de8186ece768c4b22abf98b4dba1f2c7bab389a80f10 22724 running /var/lib/isulad/engines/kata-runtime/7b0e9819871e76ea2177de8186ece768c4b22abf98b4dba1f2c7bab389a80f10 2024-02-15T09:50:36.206382616Z #0
И мы видим тут две виртуальные машины. Минутку, а почему их две?
Давайте посмотрим на вывод команд isula ps. Но мы сделаем grep по начальным символам id каждой виртуальной машины, чтобы обнаружить контейнер, за которым она приписана.
# isula ps -a | grep 3603
360301fde1b1 registry.aliyuncs.com/google_containers/pause:3.5 «/pause» 16 minutes ago Up 16 minutes k8s_POD_echo2-5575f6f55-mf9s4_test-kata_08359798-e8aa-436f-a7a3-0839529764e8_0
# isula ps -a | grep 7b0e9
7b0e9819871e be50bc6e9a73ecb65c755b3a2d8449af5746647bb15df0b4221d82c599d58b15 «docker-entrypoint…» 16 minutes ago Up 16 minutes k8s_echo2_echo2-5575f6f55-mf9s4_test-kata_08359798-e8aa-436f-a7a3-0839529764e8_0
и вспоминаем, что k8s использует для запуска каждого pod инфраструктурный контейнер pause (для тех кто забыл или не знал — он используется для резервирования сетевого namespace при создании pod).
Ну и теперь мы можем попробовать получить доступ к нашему приложению, для этого мы находим адрес, по которому мы будем обращаться командой:
$ kubectl -n test-kata get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
echo2 LoadBalancer 10.10.104.135 172.17.3.112 8080:30607/TCP 1h
Из этого вывода мы видим, что служба получила при создании адрес 172.17.3.112
Формируем запрос при помощи команды curl:
$ curl http://172.17.3.112:8080
{
«path»: «/»,
«headers»: {
«host»: «172.17.3.112:8080»,
«user-agent»: «curl/8.2.1»,
«accept»: «*/*»
},
«method»: «GET»,
«body»: «»,
«fresh»: false,
«hostname»: «172.17.3.112»,
«ip»: «::ffff:172.17.3.64»,
«ips»: [],
«protocol»: «http»,
«query»: {},
«subdomains»: [],
«xhr»: false,
«os»: {
«hostname»: «echo2-5575f6f55-mf9s4»
},
«connection»: {}
Всё, мы получили ответ от приложения, запущенного в контейнере echo2-5575f6f55-mf9s4 (мы видим это по «hostname» из ответа сервера).
Поздравляю, мы достигли нашей цели!
Выводы
Сегодня мы рассмотрели довольно необычный подход к казалось бы уже привычной процедуре запуска контейнеров. Для кого-то продемонстрированный метод покажется чересчур обезопасен, а кто-то может быть обнаружит для себя решение каких-либо своих насущных проблем. В любом случаем, подход имеет право на существование, будем следить за тем, как развиваются затронутые в статье проекты и при появлении каких-либо новых интересных функциональностей мы обязательно протестируем их и напишем об этом новую статью.
Всем спасибо за внимание!