Rubik — ещё один способ управления ресурсами в kubernetes
Что в этот раз?
Сегодня мы вновь затронем аспекты работы модного ныне решения по управлению контейнеризированными приложениями — kubernetes. А именно — рассмотрим пример эффективного управления ресурсами (CPU, память, диски и т.д.), мощности которых никогда не бывает много.
Перед тем как перейти, собственно, к описанию рассматриваемой сегодня технологии (вновь из стека дистрибутива OpenEuler), давайте для начала попробуем сформулировать ту проблему, которую призвана решить данная технология. А проблема эта кроется в том, что утилизация серверных ресурсов (если смотреть масштабно) недостаточно высока. Особенно ярко это проявляется у облачных провайдеров или крупных центров обработки данных, в ситуациях, когда для обеспечения работы каких-либо важных сервисов с непредсказуемой нагрузкой приходится или держать часть ресурсов кластера в резерве, в результате чего среднее использование ресурсов кластера крайне низкое, или пытаться запускать приложения совместно, используя механизмы QoS, встроенные в kubernetes. Тут стоит заметить, что kubernetes имеет встроенные возможности для управления QoS при доступе приложений к таким ресурсам как CPU (время использования) и память (количество использования). Но, если мы хотим ограничить наше приложение при доступе к таким ресурсам как дисковая подсистема (количество IOPS) или предоставить расширенные возможности по ограничению использования CPU приходится обращаться к каким-либо сторонним решениям или пробовать создавать что-то своё.
Одним из таких решений и является проект Rubik, который мы сегодня рассмотрим в нашей статье.
Немного теории
Теперь давайте немного отвлечёмся и попробуем вспомнить, а как собственно в данный момент организована работа с приоритетами запуска и выделением ресурсов для приложений в кластере kubernetes.
Для начала, напомним себе, что есть такая вещь как PriorityClass. Данная технология позволяет создать классы, у каждого из которых будут свои значения приоритета и затем мы можем запускать приложения, у которых мы явно указываем к какому классу приоритета принадлежит данное приложение. Но, данный метод оказывает влияние только на момент, когда control plane kubernetes занят планированием назначения узла кластера для запуска экземпляров контейнера нашего приложения. И в лучшем случае, он поможет просто «выселить» (evicted) контейнеры менее приоритетного приложения и запустить на их месте наше приложение с более высоким приоритетом. После того как приложения (важное и неважное) запустились на узлах и противоречий по запрошенным ресурсам у планировщика нет, данные классы приоритета влияния на работающее приложение не оказывают. То есть, если приложения (приоритетное и не приоритетное) запустились в рамках одного узла, то доступ к ресурсам CPU, памяти и т.д. они будут получать на равной основе.
Отлично. Теперь давайте вспомним, а как k8s управляет количеством ресурсом, которое может потребить контейнер. Для этого обратимся к квотам на выделение ресурсов.
Из прочтения этой документации мы узнаём, что у нас есть ограничения по выделению ресурсов (CPU, mem) двух видов: request и limit. Они реализованы с применением технологии cgroup ядра Linux и механизма квот планировщика CFS. Не будем особенно подробно погружаться в подробности реализации данного инструмента, позволим себе лишь отметить, что:
— запрос (requests) квота играет роль в момент планирования запуска контейнера. Величины cpu или memory в секции request выступают в качестве исходных данных для планировщика kubernetes при задаче распределения для запуска контейнеров по рабочим узлам.
— лимит (limits) квота — это «верхнее» ограничение по использованию ресурсов, которое может потребить запущенный контейнер. При превышении лимита по CPU включится механизм троттлинга, а если контейнер попробуем «захватить» больше памяти, чем ему ограничено, то к нему в гости непременно нагрянет суровый OOM.
Так же, у нас есть 3 класса обслуживания. Выбор к какому классу отнести наш pod будет зависеть, от того каким образом мы указали в описании наших контейнеров requests и limits.
Если у контейнера не будут указаны запросы и лимиты по ресурсам (это соответствует QoS классу BestEffort), то он будет запущен на усмотрение планировщика kubernetes и будет потреблять ресурсов столько, сколько он сможет потребить. Но за такую вольницу ему первому и придётся терпеть лишения в случае нехватки ресурсов для приложений, у которых эти лимиты как раз указаны. При нехватке ресурсов и начале автоматического высвобождения такие контейнеры будут уничтожаться первыми.
Если у контейнера указаны запросы и лимиты и запросы не равны лимитам (или указаны только запросы), то такие контейнеры получают класс Burstable. Да, такие контейнеры имеют приоритет перед контейнерами класса BestEffort, но они проигрывают в гонке запросов к ресурсам по сравнению со следующим классом QoS.
И получается, что если мы хотим гарантировано иметь ресурсы для запуска нашего важного приложения, то мы обязаны выставить ему requests параметры равными limits параметрам и только вы этом случае наш контейнер получить класс QoS Guaranteed.
Контейнеры такого класса всегда будут запланированы для запуска на те узлы кластера, где гарантировано есть необходимое количество ресурсов (планировщик использует для этого подсчёт на основе тех requests, которые указаны в манифейстах запуска приложений). Но это не исключает ситуации, что к ним можно подселить pod класса BestEffort, который будет получать ресурсы только в случае недоиспользования их контейнерами класса Guaranteed. Но всё описанное имеет значение только по отношению к таким видам ресурсов как CPU и память, а ведь это не единственное, что влияет на производительность приложения.
И теперь на арену выходит проект Rubik, который позволяет следующие возможности:
- Указывать какое приложение должно иметь абсолютное преимущество (preemption) перед другими (использование CPU и очерёдность срабатывания OOM), без использования PriorityClass и механизма указания запросов и лимитов.
- dynCache Memory Bandwidth and L3 Cache Access Limit (Функция ограничения доступа к кэшу и пропускной способности памяти поддерживает только физические компьютеры)
- dynMemory — многоуровневое переиспользование памяти
- flexible bandwidth. Чтобы эффективно решить проблему ухудшения качества обслуживания, вызванную ограничением пропускной способности CPU для сервиса, rubik предоставляет гибкую полосу пропускания, позволяющую контейнеру использовать дополнительные ресурсы CPU, обеспечивая стабильную работу сервиса.
- i/o weight control. Чтобы решить проблему, связанную с ухудшением качества обслуживания online сервисов из-за интенсивного использования offline сервисов при вводе-выводе, Rubik предоставляет функцию контроля веса ввода-вывода, основанную на ioCost версии cgroup v1.
В этом обзоре мы рассмотрим самый простой вариант использования — как настраивать preemption для наших приложений.
Используемый стенд
Для демонстрации rubik мы будем использовать наш стенд kubernetes версии 1.28.2. Мы уже использовали его для демонстрации другого интересного решения — KubeOS. Заинтересовавшиеся — могут ознакомится со статьёй на нашем сайте.
Наш кластер kubernetes состоит из 3 узлов — 1 мастер и 2 рабочих узла:

Каждый рабочий узел (а это виртуальные сервера) имеет 8 ядер CPU и 8 Гб оперативной памяти.
Так же нам понадобится:
— сервер под управлением openeuler 22.03 LTS (в нашем случае SP3) с установленным приложением docker, где мы будем собирать docker образ rubik.
— наш собственный внутренний registry, где мы разместим docker образ приложения rubik. В нашем случае адрес этого registry: http://172.17.1.91:5000
Подготовка серверов кластера kubernetes
Руководствуясь документацией (1) мы проведём установку rubik в виде контейнеризированного приложения на наш кластер kubernetes. Но, для начала надо заметить, что rubik работает только с драйвером cgroup v1, поэтому наши сервера kubernetes надо предварительно подготовить.
Для этого выполним ряд команд, а именно:
1) на каждом узле кластера нам надо дать команду:
grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=0"и перезагрузить сервер.
После перезагрузки, убеждаемся, что у нас cgroup смонтирована так, как она должна быть для v1:
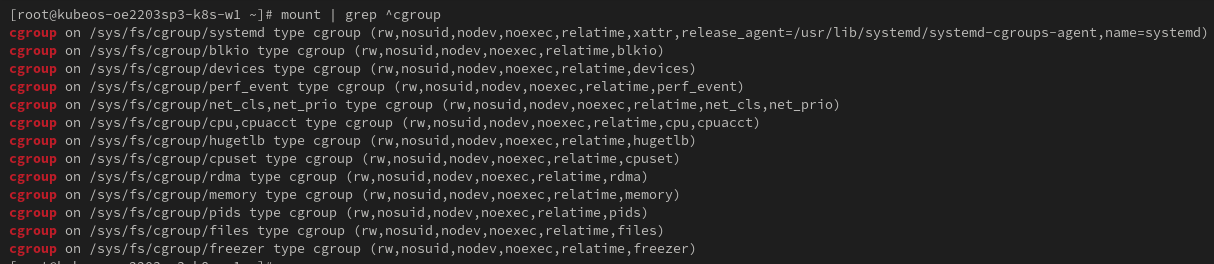
2) Теперь, надо выставить поддержку cgroup v1 в настройках используемого нами containerd в файле /etc/containerd/config.toml:
SystemdCgroup = false
И перезапустим containerd.
Сборка образа rubik
Теперь мы должны приступить к сборке docker образа rubik. Для этого мы на нашем сервере сначала ставим пакет:
dnf install rubik
Установленный пакет:
# rpm -qa | grep ^rubik
rubik-2.0.0-3.oe2203sp3.x86_64
После успешной установки этого пакета, нам надо перейти в каталог /var/lib/rubik и запустить скрипт сборки:
# ./build_rubik_image.shПосле успешного завершения работы этого скрипта, в перечне наших docker образов появится образ:

Теперь размещаем его в нашем registry по адресу:

Готово. Собственно теперь, можно приступать к запуску rubik на нашем кластере kubernetes.
Запуск rubik
Готовим yaml манифест для запуска rubik-daemonset.yaml:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rubik
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["pods/eviction"]
verbs: ["create"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rubik
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: rubik
subjects:
- kind: ServiceAccount
name: rubik
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: rubik
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: rubik-config
namespace: kube-system
data:
config.json: |
{
"agent": {
"logDriver": "stdio",
"logDir": "/var/log/rubik",
"logSize": 1024,
"logLevel": "info",
"cgroupRoot": "/sys/fs/cgroup",
"enabledFeatures": [
"preemption"
]
},
"preemption": {
"resource": [
"cpu",
"memory"
]
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: rubik-agent
namespace: kube-system
labels:
k8s-app: rubik-agent
spec:
selector:
matchLabels:
name: rubik-agent
template:
metadata:
namespace: kube-system
labels:
name: rubik-agent
spec:
serviceAccountName: rubik
hostPID: true
containers:
- name: rubik-agent
image: 172.17.1.91:5000/rubik:2.0.0-3
imagePullPolicy: IfNotPresent
env:
- name: RUBIK_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: rubiklog
mountPath: /var/log/rubik
readOnly: false
- name: runrubik
mountPath: /run/rubik
readOnly: false
- name: sysfs
mountPath: /sys/fs
readOnly: false
- name: devfs
mountPath: /dev
readOnly: false
- name: config-volume
mountPath: /var/lib/rubik
terminationGracePeriodSeconds: 30
volumes:
- name: rubiklog
hostPath:
path: /var/log/rubik
- name: runrubik
hostPath:
path: /run/rubik
- name: sysfs
hostPath:
path: /sys/fs
- name: devfs
hostPath:
path: /dev
- name: config-volume
configMap:
name: rubik-config
items:
- key: config.json
path: config.json
И при помощи kubectl применяем его:
kubectl apply -f rubik-daemonset.yaml
Убеждаемся, что pod приложения rubik успешно запустились:

Если мы посмотрим на лог запущенных контейнеров rubik, то мы увидим, что по умолчанию rubik пометил все pod которые он обнаружил в нашем кластере как online.
Запуск тестовых приложений
В самом начале статьи мы упомянули, что собираемся увидеть эффект применения rubik для реализации преимущества одного приложения над другим. Это преимущество будет выражаться во времени использования CPU. Для того, чтобы наше приложение в контейнере старалось занять работой процессор, мы просто будем высчитывать контрольные суммы файла /dev/urandom. В приложении которое у нас будет online мы будем считать sha256sum, а в приложении offline мы будем считать md5sum.
Согласно документации (1) для того, чтобы rubik отличал online от offline приложения, существует аннотация (annotation) вида:
annotations:
volcano.sh/preemptable: "true"
Значение true указывает rubik, что данное приложение является offline.
Чтобы создать конкуренцию за такой ресурс как CPU мы будем запускать все контейнеры наших тестовых приложений на одном узле (kubeos-oe2203sp3-k8s-w1). Для этого мы воспользуемся nodeAffinity при написании наших манифестов, а сам узел kubeos-oe2203sp3-k8s-w1 мы пометим специальной меткой:

Приведём yaml файлы наших приложений:
deploy-offline-rubik.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: offline-rubik
namespace: qosexample
spec:
replicas: 7
selector:
matchLabels:
app: offline
template:
metadata:
labels:
app: offline
annotations:
volcano.sh/preemptable: "true"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: test1
operator: In
values:
- "rubik"
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'md5sum /dev/urandom']
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "100Mi"
cpu: "10m"
deploy-online-rubik.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: online-rubik
namespace: qosexample
spec:
replicas: 7
selector:
matchLabels:
app: online
template:
metadata:
labels:
app: online
annotations:
volcano.sh/preemptable: "false"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: test1
operator: In
values:
- "rubik"
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'sha256sum /dev/urandom']
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "100Mi"
cpu: "10m"Для начала мы запускаем наше приложение offline:

Видим, что наши pod запустились:

Если мы запустим top на узле kubeos-oe2203sp3-k8s-w1 мы увидим ожидаемую картину:
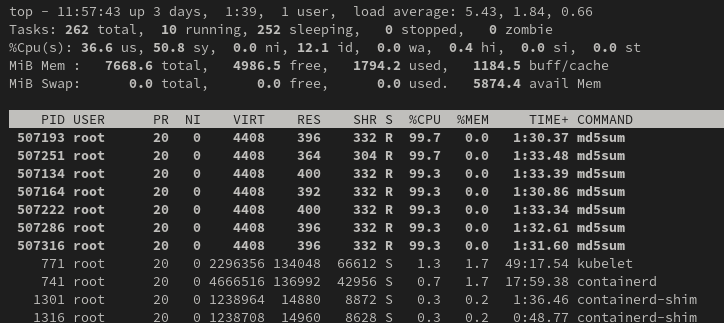
Теперь давайте запустим online приложение:

Видим, что все pod (и offline и online приложения) запущены у нас на одном узле.
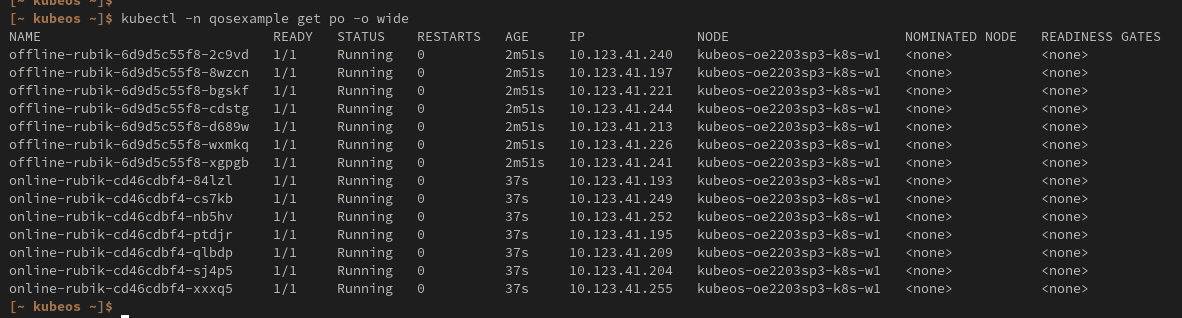
И теперь давайте посмотрим распределение по утилизации CPU:
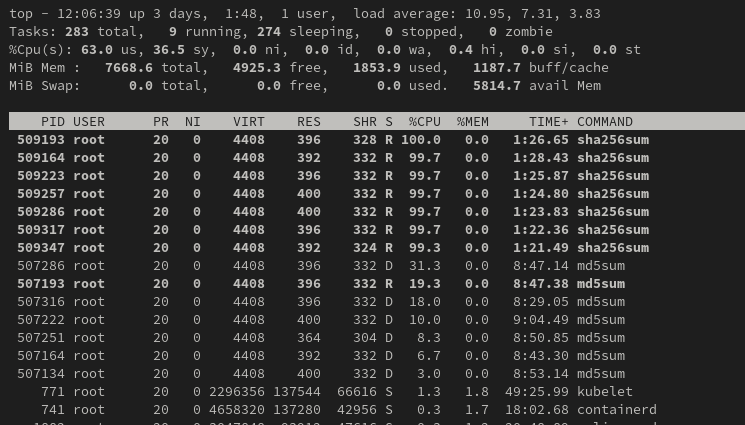
И мы чётко видим какому приложению отдан приоритет в работе.
Теперь, давайте снизим нагрузку на CPU так, чтобы на узле kubeos-oe2203sp3-k8s-w1 не стало конкуренции за ядра CPU. Для этого уменьшим количество реплик у каждого из наших приложений до 2х:

Видим, что количество pod уменьшилось:

Заглядываем в top на рабочем узле и видим, что оба приложения занимают максимум из отведённого им лимитами указанными в yaml файле:

То есть, в момент конкуренции за такой ресурс как CPU наше приложение online получает полное преимущество, при этом заметьте, что оба приложения (online и offline) у нас принадлежат одному QoS классу — Burstable и при обычном использовании делили бы ресурсы поровну.
Выводы
Сегодня мы рассмотрели довольно интересный подход к решению задачи повышения утилизации серверных ресурсов. Плюсом данной технологии является расширение возможностей стандартных систем ограничений и контроля за ресурсам kubernetes, а к минусам можно отнести работу rubik на уже устаревшей cgroup v1.
Используемая документация
- (1) https://docs.openeuler.org/en/docs/22.03_LTS_SP3/docs/rubik/overview.html
- (2) https://gitee.com/openeuler/rubik
